




Nền tảng watsonx cho AI doanh nghiệp thế hệ tiếp theo thể hiện cam kết liên tục của IBM trong việc đóng góp và sử dụng các công nghệ mã nguồn mở trong các sản phẩm của hãng.
Watsonx.data, là thành phần lưu trữ dữ liệu của watsonx, tận dụng các công nghệ mã nguồn mở đáng tin cậy ở mọi cấp độ trong kiến trúc của sản phẩm. Watsonx.data được xây dựng trên kiến trúc dữ liệu mở lakehouse, cung cấp những ưu điểm tốt nhất của cả kiến trúc data warehouse và data lake. Data lakehouse có hiệu suất cao của một data warehouse chứa dữ liệu có cấu trúc, nhưng cũng cung cấp sự linh hoạt trong việc lưu trữ kết hợp dữ liệu có cấu trúc, dữ liệu phi cấu trúc và dữ liệu bán cấu trúc từ nhiều nguồn khác nhau.
Một trong những công cụ truy vấn mã nguồn mở cho phép watsonx.data cung cấp xử lý dữ liệu nhanh chóng, đáng tin cậy và hiệu quả ở quy mô lớn là Presto.
Presto là gì?
Presto là công cụ truy vấn, một phần mềm nằm ngay lớp trên kiến trúc lưu trữ dữ liệu nền tảng và thực hiện các yêu cầu dữ liệu bằng cách tối ưu hóa quá trình truy xuất dữ liệu. Cụ thể hơn, Presto là một công cụ truy vấn phân tán cho phân tích dữ liệu data lake trên các truy vấn nhanh dạng SQL.
Presto đã trở thành mã nguồn mở vào năm 2019 khi nó được tặng cho Linux Foundation và hiện đang được quản lý bởi Presto Foundation theo mô hình mã nguồn mở.
Presto rất linh hoạt và hỗ trợ truy vấn trên nhiều nguồn khác nhau, bao gồm cả cơ sở dữ liệu quan hệ có cấu trúc như MySQL và PostgreSQL, và các nguồn dữ liệu NoSQL không có cấu trúc và bán cấu trúc như MongoDB và HBase. Tương tự, Presto hỗ trợ nhiều định dạng dữ liệu khác nhau như ORC, Avro, Parquet, CSV, JSON, và nhiều hơn nữa.
Presto sử dụng cái gọi là ‘kết nối’ để tích hợp với nhiều nguồn dữ liệu bên ngoài này. Bất kỳ nguồn dữ liệu nào cũng có thể được truy vấn miễn là nguồn dữ liệu đó thích ứng với API của Presto. Điều này làm cho Presto cực kỳ linh hoạt và có thể mở rộng.
Kiến trúc Presto
Presto có thể nhanh chóng truy vấn trên nhiều petabyte dữ liệu được lưu trữ trong các nguồn dữ liệu khác nhau vì kiến trúc của nó dựa trên mô hình xử lý song song cho dữ liệu lớn.
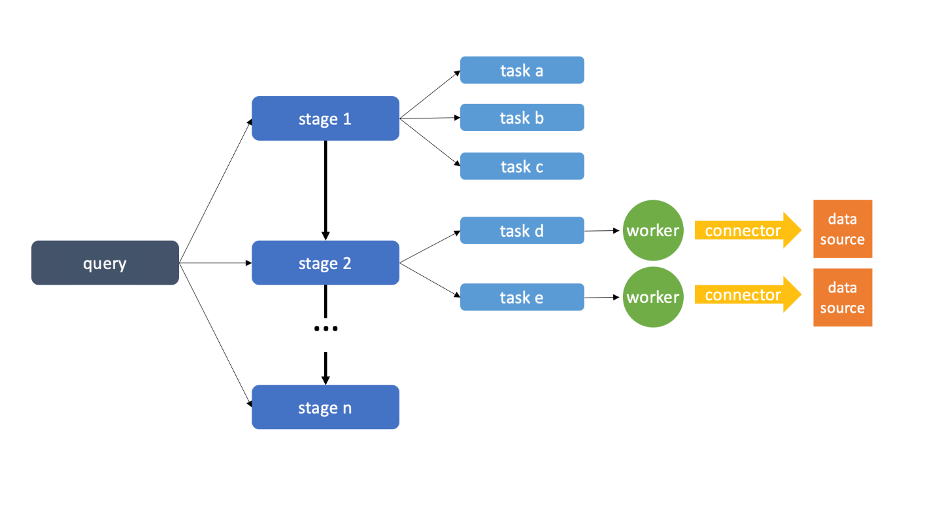
Hai loại node tạo nên kiến trúc Presto: một coordinator và một hoặc nhiều worker xử lý dữ liệu song song. Chúng ta có thể hiểu trách nhiệm của từng nút bằng cách theo dõi một truy vấn như sau:
Coordinators
Đầu tiên, người dùng gửi một câu lệnh SQL thông qua một máy client, chẳng hạn như giao diện dòng lệnh. Coordinator sau đó phân tích cú pháp truy vấn này thành một định dạng mà Presto hiểu và thực hiện một loạt các xác thực trên truy vấn. Nếu xác thực thành công, coordinator tạo ra một kế hoạch công việc tối ưu, chia truy vấn thành nhiều giai đoạn (stage) công việc để hoàn thành lần lượt. Các stage này sau đó được chia nhỏ thành nhiều nhiệm vụ.
Workers
Sau khi đảm bảo rằng có đủ số lượng tài nguyên cần thiết, coordinator phân công các nhiệm vụ này cho các nút worker. Các nút worker xử lý nhiệm vụ song song, sử dụng kết nối liên quan để truy cập vào nguồn dữ liệu gốc.
Kết nối được sử dụng có thể khác nhau giữa các worker, tùy thuộc vào cách truy vấn được tối ưu hóa và những nguồn dữ liệu nào cần được truy cập. Khi các nút worker xử lý nhiệm vụ, coordinator liên tục giám sát chúng bằng các tín hiệu kiểm tra. Khi worker hoàn thành, kết quả của các nhiệm vụ được gửi lại cho coordinator.
Coordinator sau đó có thể giao cho worker các nhiệm vụ mới tại bất kỳ stage truy vấn nào chưa thực hiện. Khi tất cả các stage hoàn thành, coordinator tổng hợp kết quả từ mỗi stage thành dạng cuối cùng theo yêu cầu của truy vấn ban đầu.
Việc truyền tải các stage truy vấn qua mạng theo cách này đảm bảo rằng bất kỳ chi phí I/O không cần thiết nào đều được tránh. Ngoài ra, tất cả quá trình xử lý đều diễn ra trong bộ nhớ và dữ liệu trung gian ở cấp độ nhiệm vụ được lưu trữ trong bộ đệm.
Tất cả các tính năng này đảm bảo rằng Presto vẫn cực kỳ hiệu quả, ngay cả ở kích thước petabyte.
Tóm tắt và các bước tiếp theo
Presto là một công cụ truy vấn phân tán cung cấp xử lý dữ liệu nhanh chóng, đáng tin cậy và hiệu quả ở quy mô lớn.
Ngoài hiệu quả và tính chất mở rộng vốn có của Presto, watsonx.data cũng cho phép người dùng khởi động nhiều công cụ Presto tùy thuộc vào nhu cầu công việc. Điều này có nghĩa là người dùng có thể chọn đúng công cụ cho đúng khối lượng công việc và với số lượng phù hợp, tất cả đều được hỗ trợ bởi các công nghệ mã nguồn mở đáng tin cậy.
Nếu bạn muốn có một nền tảng cấp doanh nghiệp để truy vấn lượng dữ liệu đa dạng lớn với SQL, chắc chắn hãy thử qua watsonx.data hoặc khám phá thêm bài viết và hướng dẫn cho watsonx.
Link tham khảo:


